
Perspectives on AI Symposiums
February 21, 2024
Idiap Research Institute, Martigny, Switerland.
Idiap Research Institute, Martigny, Switerland.
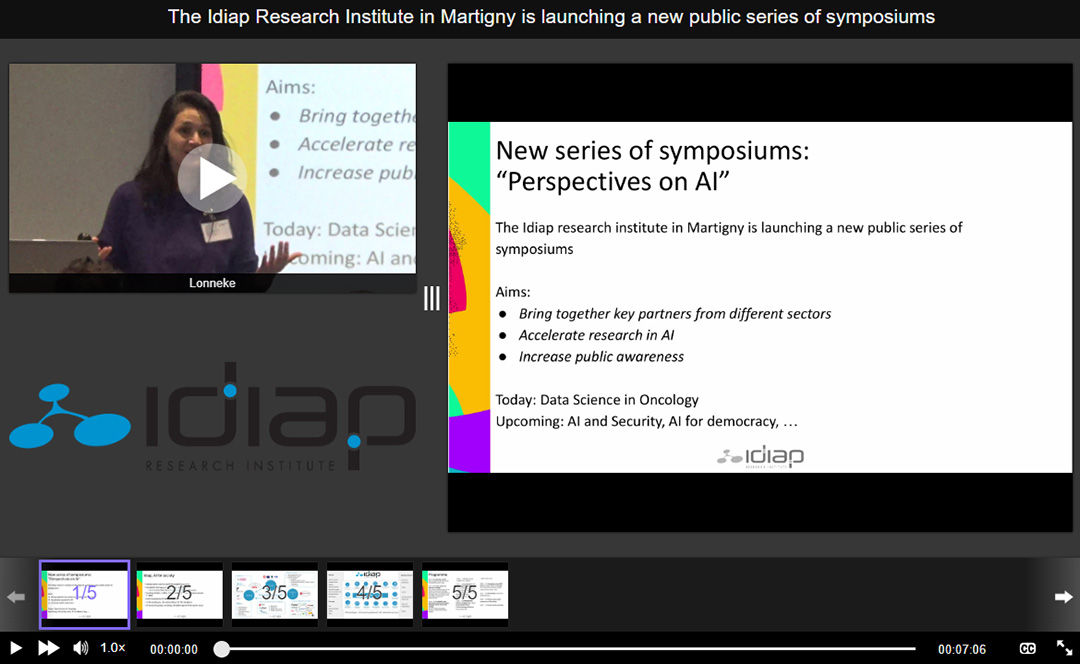
Idiap is launching a new public series of symposiums entitled:
These events aim to bring together academia, industry and policy makers to present their perspectives on artificial intelligence, in particular how we can leverage the power of AI to address key societal and industrial challenges.
This symposium will discuss how data science and AI support the research and development in oncology, and what are the current limitations, such as data sharing and privacy, or the interpretability of the algorithms, as well as what can be done to accelerate the research.
Keynote speakers are Prof. Olivier Michielin (Head of the Center of Precision Oncology, Department of Oncology, CHUV), Dr. Jean Hausser (Assistant Professor, Karolinska Institute), Dr. Slavica Dimitrieva (Associate Director and Senior Principal Scientist, Novartis Institute for Biomedical Research), and Dr. Maria Rodriguez Martinez (Group Leader, IBM). The round-table will be animated by Prof. Benoit Dubuis (Director, Fondation Campus Biotech Geneva) to which Prof. Elisa Oricchio (Director of ISREC and Professor at EPFL) and members of the Oncology in Valais Hospital will take part.
During this round table animated by Dr Benoit Dubuis, participants, including speakers, researchers from HES-SO and Idiap, and clinicians from Valais Hospital, will discuss possibilities, opportunities, and challenges that data science and AI offers for the oncology clinical research.
The three best posters will be rewarded ! See below.
In the past decade, deep learning became the predominant paradigm for thinking about Artificial Intelligence. However, there are many relevant scenarios where traditional deep learning methods alone are not fit-for-purpose, where large training data is not available or data is too heterogeneous and multi-modal. This compounds with the need for many critical application areas that require interpretability to be at its center, or the lack of resources to build large models. Examples where these requirements are the norm are abundant: from clinical trials, through the analysis of complex customer / behavioural / environmental data, to policy making.
In this Perspectives on AI edition, we will discuss emerging methods which are outside the traditional deep learning and statistics toolbox, aiming to address these challenges. Under the ethos of 'Doing more with less', invited speakers from academia and industry will discuss how recent methodological developments in AI and statistical methods can address existing challenges and deliver new opportunities for making sense of an increasingly complex data landscape.
The event is targeted towards academics, data scientists, practitioners and executives who need to make sense of complex, heterogeneous and small data and it aims to discuss the following questions:
Prof. Elizabeth Tipton is an Associate Professor of Statistics, the Co-Director of the Statistics for Evidence-Based Policy and Practice (STEPP) Center, and a Faculty Fellow in the Institute for Policy Research at Northwestern University. Tipton's research focuses on the design and analysis of field experiments, with a particular focus on issues of external validity and generalizability in experiments; meta-analysis, particularly of dependent effect sizes; and the use of (cluster) robust variance estimation. Tipton earned her PhD in Statistics from Northwestern University in 2011. In 2005, she earned an M.A. in Sociology from the University of Chicago and in 2001 a B.A. in Mathematics from Transylvania University in Lexington, Kentucky. Prior to returning to Northwestern University, she was a member of the faculty at Teachers College, Columbia University for seven years. In 2020, she received the Frederick Mosteller Award.
Prof. Alexandros Kalousis is a Professor at the University of Applied Sciences, Western Switzerland in the Geneva School of Business Administration, where he leads the Data Mining and Machine Learning group. He also holds a "Chargé de Cours" position in Department of Computer Science at the University of Geneva. He received his PhD from the University of Geneva in the area of machine learning. He has a BSc and MSc in Computer Science in the University of Athens, Greece. Over the years he has explored a variety of research problems, such as metric and kernel learning, feature selection and dimensionality reduction, regularisation, and meta-learning. He is currently exploring different research problems such as structured regularisation, learning of dynamical systems, life-long learning, imitation and reinforcement learning, many of them using deep learning methods.
Cédric Travelletti completed his PhD in Statistics under the supervision of David Ginsbourger at the University of Bern in June 2023. Before his PhD, he obtained an MSc in Physics at ETH Zürich and worked as a data scientist at SwissRe and Deloitte. His research focuses on the computational and theoretical aspects of Bayesian inversion. He is particularly interested in developing sequential uncertainty reduction strategies for set estimation in large-scale inverse problems. Recently, his research has been devoted to creating more realistic uncertainty reduction models, either through the inclusion of expert knowledge or through constrained path planning.
Dr Andreas Loukas is a Senior Principal Scientist and Machine Learning Lead at Prescient Design. His work focuses on the foundations and applications of machine learning to structured problems. He aims to find ways to exploit (graph, constraint, group) information, with the ultimate goal of designing algorithms that can learn from fewer data. He is also focusing on the theoretical analysis of neural networks and in using them to solve hard bioengineering problems (especially protein design). Andreas obtained his Ph.D. in computer science from TU Delft in 2015 and pursued postdoctoral studies at TU Berlin and EPFL. He became an SNSF Ambizione fellow at EPFL in 2018 and an Assistant Professor at the Computer Science department of the University of Luxembourg in 2021. He joined Genentech/Roche in 2022.
Dr Dorina Thanou is a senior research scientist and lecturer at EPFL, leading the development of the Intelligent Systems for Medicine and Health research pillar, under the Center for Intelligent Systems. Prior to that, she was a Senior Data Scientist at the Swiss Data Science Centre. She got her M.Sc. and Ph.D. in Communication Systems and Electrical Engineering respectively, both from EPFL, Switzerland, and her Diploma in Electrical and Computer Engineering from the University of Patras, Greece. She is the recipient of the Best Student Paper Award at ICASSP 2015, and the co-author of the Best Paper Award at PCS 2016. Her research interests lie in the broader area of signal processing and machine learning and she is particularly interested in applying her expertise to intelligent systems for biology and medicine. She is an ELLIS Scholar.
Abstract: There is an increasing need for evidence-based practices in a variety of fields, from education to development to medicine. Buttressing this evidence base are improvements in methods for causal inference – from advanced experimental designs to methods for observational studies. As the field of evidence-based practice has matured, however, it has become clear that there is a disconnect between these methods – which prioritize internal validity – and the needs of decision makers – which prioritize external validity. I begin by reviewing this problem (with a focus on applications in education and psychology) and then propose how causal inference research might better incorporate these external validity concerns. This will include a review of methods for generalizing results from samples to populations and methods for exploring treatment effect heterogeneity. Much of the talk will focus on how to better design studies to meet both internal and external validity goals.
Abstract: We introduce AbDiffuser, an equivariant and physics-informed diffusion model for the joint generation of antibody 3D structures and sequences. AbDiffuser is built on top of a new representation of protein structure, relies on a novel architecture for aligned proteins, and utilizes strong diffusion priors to improve the denoising process. Our approach improves protein diffusion by taking advantage of domain knowledge and physics-based constraints; handles sequence-length changes; and reduces memory complexity by an order of magnitude enabling backbone and side chain generation. We validate AbDiffuser in silico and in vitro. Numerical experiments showcase the ability of AbDiffuser to generate antibodies that closely track the sequence and structural properties of a reference set. Laboratory experiments confirm that all 16 HER2 antibodies discovered were expressed at high levels and that 57.1\% of selected designs were tight binders.
Abstract: An inverse problem is the task of reconstructing an unknown physical phenomenon via indirect observations thereof. Such problems arise in many areas of the natural sciences, from geology to climatology. Instead of reconstructing the whole unknown phenomenon, one may be interested in estimating regions in space that are defined by conditions on said phenomenon. Examples include: high curvature regions, regions where a physical quantity exceeds a given threshold, etc. In this talk, we present methods for computing data collection plans that aim at reducing the uncertainty on such target regions arising in inverse problems. We focus on cases where data is expensive to collect and present methods that leverage pre-existing expert knowledge to compensate for the sparsity of the data. We will demonstrate our techniques on a river plume estimation problem and a volcano gravimetric inversion problem.
Dr Andreas Loukas, Dr Dorina Thanou
Panel discussion
Prof. Matteo Valleriani is Research Group Leader at the Max Planck Institute for the History of Science in Berlin, honorary professor at the Technische Universität of Berlin, professor by Special Appointment at the University of Tel Aviv and PI at The Berlin Institute for the Foundations of Learning and Data (BIFOLD). He investigates epistemic processes of transformation of scientific knowledge focusing on past eras and in particular on the Hellenistic period, the late Middle Ages, and the early modern period. Among his principal research endeavors, he leads the project “The Sphere: Knowledge System Evolution and the Shared Scientific Identity of Europe” (https://sphaera.mpiwg-berlin.mpg.de). In his research, Matteo Valleriani implements the development and the application of Machine Learning technology and the physics of complex systems.
Dr. Silvia Quarteroni holds an MSc in Computer Science from EPFL and a PhD in Computer Science from the University of York, UK. She has been a senior research fellow at the University of Trento and later at Politecnico di Milano, Italy. Here, she had the chance to work on Marie Curie and ERC projects relating to natural language processing. From 2012 to 2019, she was a Senior Manager and NLP expert at ELCA Informatique Switzerland, whose AI department she helped create and expand. Silvia joined the Swiss Data Science Center in 2019 and is currently its Chief Transformation Officer, in charge of the team leading organizations to digital transformation.
Dr André Freitas leads the Neuro-symbolic AI Group at the Idiap Research Institute and is a Senior Lecturer (Associated Professor) at the Department of Computer Science at the University of Manchester. He is also the AI group leader at the digital Experimental Cancer Medicine Team (CancerResearchUK Manchester Institute). His main research interests are on enabling the development of AI methods to support abstract, explainable and flexible inference. In particular, he investigates how the combination of neural and symbolic data representation paradigms can deliver better inference. Some of his research topics include: explanation generation, natural language inference, explainable question answering, knowledge graphs and open information extraction. He is actively engaged in collaboration projects with industrial and clinical partners.
Al Brown
Silvia Quarteroni
Juliette Lemaignen
Gangadhar Garipelli
This symposium explores how AI impacts security, privacy, law and ethics. It aims to understand what can we do to resolve the issues and risks posed by AI, while still benefiting from its power. The symposium aims to be a discussion and collaboration platform between academic research and applied industry, facilitating technology transfer and innovative solutions.
The symposium consists of three sessions, each including one keynote and several short presentations. The first session centers on security vulnerabilities of AI models and general privacy concerns. The second session delves into the legal and ethical aspects of AI, exploring such issues like accountability, transparency, and fairness. An interesting question is what impact on society AI has and will have in the future. The third session highlights the intersection of AI, health, and medical science, particularly the security issues associated with AI in healthcare. The focus is on the potential risks and benefits of AI adoption in the medical field, including patient personal information protection and the security of medical records.
The recent developments in AI, notably generative AI, have invigorated discussion on the role and impact of AI on democracy. On the one hand, AI is an opportunity to improve democratic processes in our societies, for example AI can help finding sources of misinformation, and help citizens to better understand politics and engage more easily in democratic debate. On the other hand, it raises concerns about AI undermining democracy, precisely because the tool can be used to spread false information and influence public behaviour.
In this Perspectives on AI seminar, we aim to bring together academics, industries, NGOs and politicians to discuss the opportunities and risks of AI for democracy.
Abstract: The media is considered a pillar democratic institution, but can artificial intelligence obscure or illuminate it? We explore how journalistic accountability can navigate algorithms, risks of manipulation and the crucial role of transparency in safeguarding democracy.
Abstract: Artificial intelligence (AI) and other new technologies have the potential to fundamentally change all areas of life including the Federal Administration itself. The Competence Network for Artificial Intelligence (CNAI) of the Swiss Federal administration facilitates the sharing of knowledge and access to the competence of numerous experts in the field of AI. The CNAI also fosters public trust by transparently communicating about ongoing AI projects within the Federal Administration.
Abstract: Misinformation is considered one of the major challenges of our times resulting in numerous efforts against it. Fact-checking, the task of assessing whether a claim is true or false, is considered a key weapon in reducing its impact. In this talk I will present our recent and ongoing work on automating this task using natural language processing focusing on the importance of accompanying verdicts with evidence and justifications.
Abstract: Few aspects impact businesses more than regulation. However, monitoring and reporting on public affairs is a tedious and costly process for companies and associations. DemoSquare develops state-of-the-art AI algorithms to collect, monitor, analyze, and report on legislative activities, so companies of all sizes can effectively defend their business position. In a transparency effort to reinforce trust in democracy, our platform is publicly available to NGOs, journalists, academics, and citizens. We also collaborate with Le Temps and the NZZ to provide real-time predictions of elections and popular votes in Switzerland.
Abstract: Algorithmic governance driven by artificial intelligence systems is invading all of society's fields of action and sectors of activity. The scope of cyber threats and the intensity and scale of cyber attacks are only increasing. Although AI can be part of the solution, its abuse and misuse, as well as its use for criminal and conflict-related purposes, are problematic. In this context, we will analyze what AI is doing to security and democracy, and ask whether we are sufficiently aware of and prepared for the issues at stake and the civilizational challenges it poses.
Abstract: While textual evidence in web documents is the gold standard to verify the output of language models, large amounts of online content use structure to organize and communicate data more effectively. However, this structure is often overlooked. Through this talk, we will show how models can be taught to find and interpret visual language such as tables, charts and infographics, with the goal of producing text that is more faithful to its sources.
Abstract: With the recent surge of publicly available AI technologies like Chat GPT, the threat AI may pose to democracy has become an important topic. Given concerns over the past decade about the rise of populist authoritarianism in the United States and Europe—notably the demonization of political opponents, threats to voting, and refusal to accept electoral losses—do recent developments in AI further exacerbate these concerns? Using research from political psychology, I identify factors such as emotional amplification and echo-chamber effects that may potentially worsen these concerns and further destabilize democracies. I will also propose several ideas about how we might attenuate AI’s potential negative impacts on the democratic process.
Abstract: The rise of Artificial Intelligence (AI) presents both exciting opportunities and significant challenges for democratic societies. Its opaque nature and potential for bias, misinformation and risks of manipulation raise critical legal and ethical concerns that threaten the core principles of democracy. Using real-world use cases to illustrate the potential impact of AI on democratic values, this talk will explore these concerns from a legal perspective, in particular in light of the forthcoming EU AI Act.
Abstract: Online voting advice applications like Smartvote have become increasingly popular over the years. And the development will not stop. The advent of AI opens up new opportunities, but also creates pitfalls. Which aspects are particularly important for strengthening democracy and which paths will be problematic? The presentation will shed light on the topic using the example of the successful Swiss voting advice tool Smartvote.
Abstract: Data and AI radically increase rapidly the complexity of the economy and society (products, the supply / value chains, services, business models), which inevitably leads to increased complexity in the relationships between businesses and people. These new types of relationships are often not covered by legislation, due to the rapid development of technology. New laws need to face multi-dimensional issues, mixing social, legal, political, technologies. For citizens, it is becoming difficult to find their way through this maze of arguments. How will AI affect the way citizens vote when issues such as these are at stake in the democratic process? One possible approach is the development of intelligent AI assistants that will be able to map the consequences of policy decisions, taking into account all the parameters affecting a given issue. However, the neutrality of these tools can be questioned. Assuming that this issue is solved, and assuming that AI knows the profound being of each individual, then is there any reason that the person’s votes cannot be replaced by AI vote?
Abstract: Can we trust the outputs of our (large) language models? This question has become more relevant lately with the widespread adoption of LLMs. I will briefly review hypotheses on how hallucinations emerge. I will then review both black box and white box methods on how to detect them, and end with proposals for their prevention.
Abstract: The proliferation of misinformation represents a threat to democracies. Given the speed and intensity with which misinformation spreads online, there is a pressing need to understand its language and to develop detection models. Towards this goal, we have built two large corpora aimed at understanding the language of conspiracy theories (LOCO) and dubious information surrounding politically polarizing topics (DONALD). Texts are obtained from webpages coming from websites pre-evaluated for information quality and political slant. What makes these corpora valuable is that documents are matched by topic (e.g., Lady Diana’s death, abortion, climate change, etc), facilitating within-topics comparisons and allowing to identify linguistic markers of misinformation. LOCO and DONALD are also rich in data and metadata, encompassing document dates, semantic indexing, domain information, and social media engagement metrics. The talk concludes with a discussion about the challenges and opportunities these corpora present.
 — Estelle Pannatier AlgorithmWatch
— Estelle Pannatier AlgorithmWatch













On-site
Industry.
On-site
Academia.
On-site Students.
(BSc, MSc, PhD)






























